
La temperature nei prompt è uno dei parametri chiave che influenzano il modo in cui un’intelligenza artificiale genera risposte. Se stai usando ChatGPT o strumenti simili, potresti aver visto anche i termini top-p e token.
Ma cosa significano davvero?
E perché è utile saperli regolare?
In questa guida chiara e accessibile, pensata per chi non ha un background tecnico, scoprirai come questi parametri influiscono sulla creatività, precisione e lunghezza delle risposte generate dall’AI. Se stai creando un prompt per lo studio, per scrivere contenuti o per migliorare l’assistenza clienti, capire questi concetti ti aiuterà a ottenere risultati migliori.
Alunia è un servizio specializzato in chatbot AI per aziende, siti web, agenzie e professionisti. Scopri come migliorare i tuoi risultati con soluzioni intelligenti su Alunia.
Cosa significa “temperature” nei prompt AI?
La temperature è un parametro fondamentale che influenza il livello di creatività nelle risposte generate da un modello linguistico. Viene espressa con un valore numerico tra 0 e 1 e determina quanto l’AI si discosta dalle opzioni più prevedibili per scegliere parole o frasi alternative.
Più bassa è la temperatura, più il modello seguirà risposte già viste, affidabili e lineari. Aumentando il valore, l’AI avrà maggiore libertà di esplorazione semantica, con risultati più variabili, originali o talvolta incoerenti.
La seguente tabella illustra le principali soglie di temperature e il loro impatto pratico:
| Valore | Comportamento dell’AI | Esempio pratico |
|---|---|---|
| 0.0 | Completamente deterministica | Risposte identiche a ogni esecuzione |
| 0.3 | Più precisa che creativa | Ideale per sintesi tecniche e risposte chiare |
| 0.7 | Creatività bilanciata | Adatta a contenuti originali ma coerenti |
| 1.0 | Massima varietà e imprevedibilità | Utile per idee nuove, ma meno affidabile |
La scelta del giusto valore di temperature dipende dal contesto d’uso e dall’obiettivo del prompt. Non esiste un’impostazione universale: ogni scenario richiede un livello calibrato.
Quando usare temperature basse
Temperature tra 0.0 e 0.3 sono perfette per prompt in cui la coerenza e l’accuratezza sono essenziali. Riducendo l’imprevedibilità, si ottengono risposte consistenti, ripetibili e aderenti alle informazioni note dal modello.
Ideale per:
- Compiti accademici o contenuti tecnici, dove serve precisione
- Assistenza clienti, in cui sono necessarie risposte chiare e dirette
- Contenuti regolamentati, come policy o documentazione legale
Se lavori nell’ambito del supporto, puoi trovare utili esempi nella pagina dedicata ai prompt per supporto clienti, con template pensati per risposte rapide e personalizzate.
Quando usare temperature alte
Temperature comprese tra 0.7 e 1.0 sono indicate per generare risposte creative, variegate o fuori dagli schemi. L’AI esplora opzioni linguistiche meno ovvie, con maggiore varietà stilistica.
Indicata per:
- Storytelling e copywriting, dove serve inventiva
- Naming e branding, in cerca di proposte originali
- Brainstorming, per esplorare diverse angolazioni sullo stesso tema
Questi valori sono utili quando l’obiettivo è sorprendere o coinvolgere, come mostrato nella guida al copywriting con i prompt, che offre strategie e spunti per scrivere contenuti coinvolgenti usando l’intelligenza artificiale.
Che cos’è il top-p e come si differenzia dalla temperature?
Il parametro top-p, noto anche come nucleus sampling, è un’alternativa al più comune valore di temperature e serve a gestire la varietà delle risposte AI in modo più selettivo. Invece di ampliare o ridurre la creatività in modo diretto, come fa la temperature, il top-p agisce sulla probabilità cumulativa delle parole che l’AI può scegliere.
La probabilità cumulativa è il modo in cui l’AI sceglie solo tra le parole più probabili, scartando quelle meno adatte per dare risposte più controllate.
Con top-p = 1, il modello prende in considerazione l’intero vocabolario disponibile, mentre con top-p = 0.5, restringe la scelta al 50% delle opzioni più probabili. In pratica, l’intelligenza artificiale ignorerà tutte le alternative che, sommate, superano questa soglia probabilistica.
Questa tecnica consente di concentrare le risposte entro un intervallo più mirato, mantenendo comunque un certo grado di variabilità. È particolarmente utile quando si desiderano output coerenti, ma non completamente deterministici.
Puoi combinare temperature e top-p nello stesso prompt, ma è buona prassi modificarne uno alla volta. In questo modo puoi osservare l’effetto di ogni parametro in modo isolato e migliorare la qualità dei risultati generati.
Meglio usare temperature o top-p?
La scelta tra temperature e top-p dipende dal tipo di controllo che desideri avere sulle risposte dell’AI e dal contesto in cui stai operando.
Quando scegliere la temperature:
- Se vuoi un controllo più intuitivo e semplice
- Per prompt creativi, generici o a scopo sperimentale
- Quando è importante gestire la quantità di variabilità nella risposta
Quando preferire il top-p:
- In ambiti dove serve coerenza con una lieve flessibilità
- Per utilizzi professionali o aziendali, come contenuti informativi o customer care
- Quando lavori con prompt ripetitivi e desideri evitare variazioni imprevedibili
Top-p è particolarmente indicato per chi ha già esperienza con il prompt design e cerca una regolazione fine del comportamento del modello.
Se stai iniziando ora a scrivere comandi efficaci, puoi approfondire i concetti di base nella guida introduttiva al Prompt Engineering, dove trovi spiegazioni pratiche, esempi applicabili e indicazioni utili anche per chi parte da zero.
Cosa sono i token e perché contano nei prompt

Nel contesto dell’intelligenza artificiale, i token rappresentano le unità minime di testo che il modello legge, elabora e genera. A differenza delle parole, i token possono includere anche parti di parola, punteggiatura o spazi. Capire come funzionano è essenziale per scrivere prompt efficaci e controllare la lunghezza delle risposte.
Ogni modello AI ha un limite massimo di token che include sia il testo del prompt che quello della risposta generata. Se questo limite viene superato, il contenuto in eccesso verrà tagliato, compromettendo la qualità dell’output o interrompendolo in modo imprevisto.
Esempi di token
Gli esempi seguenti chiariscono come funziona la suddivisione del testo in token:
"ChatGPT"→ 1 token"scrittura creativa"→ 2 token"L’intelligenza artificiale è utile."→ 7 token
Questa segmentazione dipende dalla codifica utilizzata dal modello. Anche parole brevi o apparentemente semplici possono generare più token del previsto, specialmente in lingue diverse dall’inglese.
Per riferimento, ecco i limiti massimi di token dei modelli più utilizzati:
| Modello AI | Token massimi |
|---|---|
| ChatGPT 3.5 | Circa 4.096 token |
| ChatGPT 4 | Fino a 32.000 token |
Superare questi limiti può comportare risposte troncate o errori di elaborazione, soprattutto in conversazioni lunghe o complesse.
Come usare i token nei tuoi prompt?
Per ottimizzare l’uso dei token e migliorare l’efficacia dei tuoi prompt, segui queste indicazioni pratiche:
- Sii chiaro e diretto: evita frasi troppo lunghe o complesse
- Rimuovi parole superflue: non appesantire il prompt con dettagli inutili
- Specifica solo ciò che serve: concentrati su istruzioni essenziali
- Evita ripetizioni: riduci ridondanze per lasciare spazio alla risposta
Questo approccio è particolarmente utile per chi studia o crea sintesi di testi. Puoi partire con alcuni prompt già pronti nella pagina dedicata ai prompt per studenti: riassunti chiari e spiegazioni, pensati per sfruttare al meglio la capacità di sintesi dell’AI.
Come usare temperature, top-p e token nei tuoi prompt
Per ottenere risposte più utili e coerenti dai modelli di intelligenza artificiale, è fondamentale saper regolare in modo mirato i tre parametri chiave: temperature, top-p e token. Questi elementi, se usati correttamente, permettono di personalizzare profondamente il comportamento del modello in base al contesto e agli obiettivi del prompt.
La combinazione ideale dipende dal tipo di contenuto che vuoi generare: informativo, creativo, tecnico o conversazionale. Impostare i valori giusti ti consente di bilanciare originalità, affidabilità e lunghezza della risposta, ottimizzando il prompt in funzione del risultato desiderato.
Esempi di configurazioni ottimali
La seguente tabella mostra alcune configurazioni efficaci per diversi obiettivi d’uso. I valori sono indicativi e pensati per offrire una base su cui iniziare a sperimentare:
| Obiettivo | Temperature | Top-p | Max Token |
|---|---|---|---|
| Riassunto accademico | 0.3 | 1.0 | 800 |
| Scrittura creativa | 0.9 | 1.0 | 1000 |
| Risposta per assistenza | 0.2 | 0.9 | 400 |
| Generazione codice | 0.4 | 1.0 | 600 |
Ogni configurazione risponde a una specifica esigenza:
- Temperature basse e top-p elevati per massima coerenza e affidabilità
- Temperature alte per maggiore varietà e creatività
- Token calibrati per evitare risposte troncate e sfruttare appieno la capacità del modello
Queste impostazioni sono particolarmente utili in ambiti come lo sviluppo software. Se vuoi generare codice o fare debug in modo più efficiente, puoi iniziare dai prompt per programmatori: codice e debug AI, pensati per scenari pratici e adatti anche a chi è alle prime armi.
Per risultati ancora più precisi, puoi anche sperimentare con i prompt avanzati per risposte migliori, che ti aiutano a combinare correttamente struttura, contesto e parametri tecnici.
Impostazioni prompt in ChatGPT
Comprendere la teoria è fondamentale, ma vedere dove e come applicare i parametri temperature, top-p e token rende il tutto più immediato. Nella versione avanzata di ChatGPT (accessibile con l’abbonamento Plus), puoi personalizzare questi valori direttamente attraverso l’interfaccia dedicata alla modalità custom GPT o usando plugin e strumenti avanzati come il playground di OpenAI.
Qui sotto trovi uno screenshot rappresentativo che evidenzia le tre aree chiave:
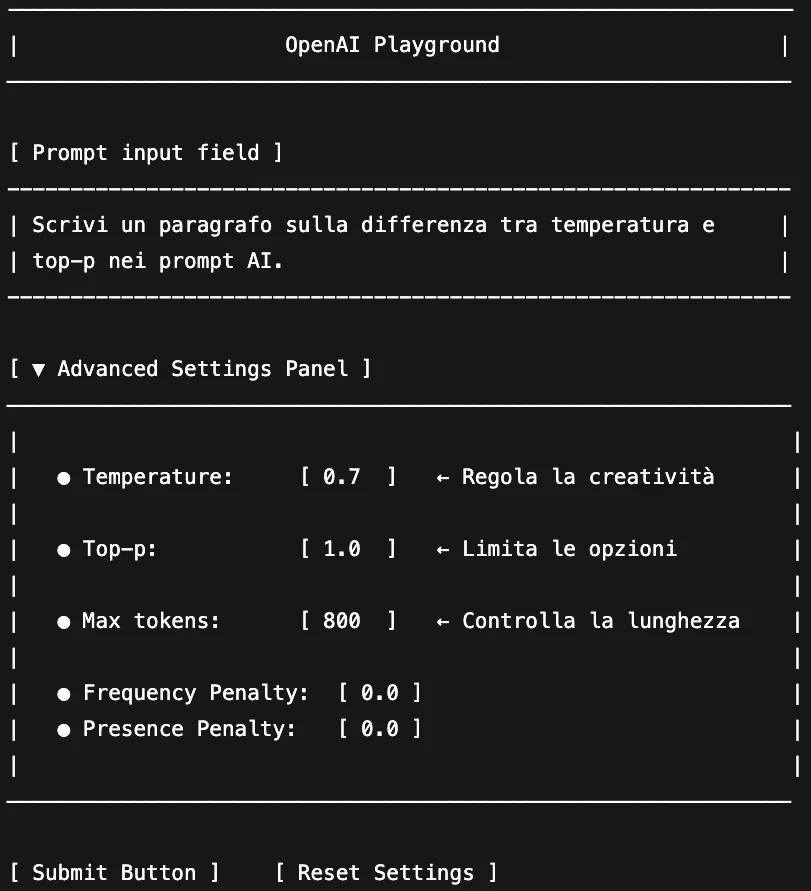
Nella sezione Temperature, puoi regolare la creatività della risposta.
Con Top-p, controlli la probabilità cumulativa per la selezione delle parole.
Il campo Max Tokens ti consente di definire la lunghezza massima dell’output, compreso il prompt iniziale.
Queste impostazioni sono accessibili anche nel Playground di OpenAI, strumento utile per chi vuole sperimentare diverse configurazioni prima di integrarle in un flusso di lavoro o in un prompt personalizzato.
Se desideri imparare a configurare questi parametri in modo strutturato, ti consigliamo di iniziare dal corso gratuito di Prompt Engineering per ChatGPT, pensato per chi vuole migliorare le performance senza essere esperto di linguaggi di programmazione.
Errori comuni da evitare
Anche con una buona comprensione dei parametri temperature, top-p e token, è facile commettere errori che compromettono l’efficacia del prompt. Questi sbagli non solo riducono la qualità delle risposte, ma possono anche generare output incoerenti, troppo brevi o inutilizzabili in contesti professionali.
Ecco gli errori più frequenti e come evitarli:
- Usare temperature troppo alte per risposte tecniche
Un valore elevato può introdurre variabilità indesiderata in contesti in cui la precisione è fondamentale, come spiegazioni accademiche, assistenza clienti o documentazione. - Ignorare i limiti di token del modello
Se il tuo prompt è troppo lungo, o se non consideri lo spazio necessario per la risposta, rischi di superare il limite di token. Il risultato sarà una risposta interrotta o incompleta. Scopri come evitare questo problema usando prompt sintetici, come mostrato nella guida ai prompt per studenti, dove ogni token è ottimizzato per massimizzare la resa. - Modificare troppi parametri insieme senza un criterio
Cambiare contemporaneamente temperature, top-p e numero di token rende difficile capire quale modifica ha avuto un impatto positivo o negativo sul risultato.
✔️ Consiglio pratico:
Modifica un solo parametro alla volta, osservando con attenzione come cambia la risposta dell’AI. Questo approccio ti aiuta a isolare il comportamento del modello e ti consente di adattare con precisione ogni impostazione al tuo obiettivo.
Per approfondire strategie strutturate, puoi consultare la guida completa alla scrittura di prompt efficaci, che include esempi concreti e tecniche per evitare errori comuni nell’uso dei parametri AI.
Conclusione
Conoscere il significato di temperature nei prompt, top-p e token ti dà un vantaggio concreto: puoi scrivere richieste più precise e ottenere risposte dall’AI che siano davvero utili, sia in ambito professionale che creativo.
👉 Se vuoi fare un salto di qualità, inizia a ottimizzare i tuoi prompt partendo da una base solida.
🔗 Scopri la guida ai prompt: istruzioni, contesto e struttura
📚 Per approfondire i termini tecnici più usati nel mondo AI, consulta il glossario ufficiale OpenAI
Riepilogo utile
- Temperature bassa → Risposte più coerenti e prevedibili
- Top-p basso → Contenuto più controllato e preciso
- Token → Gestisci spazio e lunghezza delle risposte
- Regola un solo parametro alla volta per test efficaci
- Adatta i parametri in base allo scopo del prompt (studio, contenuti, codice…)
💡 Vuoi ottenere di più con l’intelligenza artificiale?
➡️ Scopri le soluzioni AI su misura di Alunia per aziende, agenzie e professionisti.



{kind=link}